But you shouldn’t be worried about that. We should have a better strategy in uploading the files to ensure we can support larger set of input files. There are also options to pickle the Honeybee model instead of writing them as JSON. @chriswmackey, what would be the best approach to test using the pickled file? Am I right that the model handlers can work with a pickled file right now?
After doing some more digging with @mingbo and @antoinedao, we found that, for the job that started before its artifacts were uploaded your Grasshopper script successfully made 256 upload requests to our API, but only uploaded 204 files to our storage service.
This is able to happen because the clients have to first request a link to use from our API and then use that link to actually transfer the file directly to the storage servers.
Something about the upload process or the script caused the actual file transfer to fail for some files. Additionally, the file that I mentioned above that was uploaded around 02:19 seems to have arrived much later than the others (2 minutes vs. ~2 seconds).
Without knowing more about what was happening in GH, it’s hard to say why this happened. It could have been an error from the upload, a network interruption, or something about the way the script was executed. It seems like something exceptional since you were able to upload all of the files for your daylight study without an issue and the number and sizes of the files are nearly identical.
I’m going to update the SDK that Grasshopper uses to be a bit more resilient and to log more information about uploads. In the meantime, if you can get this to happen reliably, please let us know so that we can have a good test case to track down the issue.
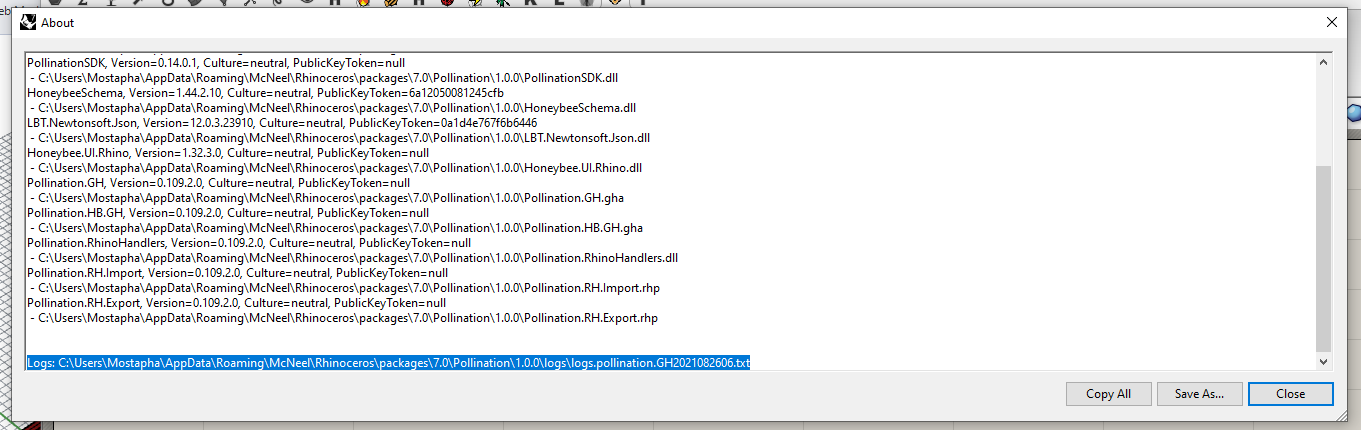
Pro tip: you can see the logs in Grasshopper by right-clicking and selecting “About”:
The log file will be the one on the line that looks like this:
Is there a way to share the .gh/.3dm files in a way that is confidential so that you can have a look through it to see what the issue is?
Thanks for the pro-tip. Very handy to know. Could it potentially be that colibri is skipping iterations and not fully calculating the results before sending off the model to the data recorder. I know that colibri has issues when parsing results completely, so I could have a look at that?
Yep! You can always email one of us. Our emails are on our Discourse profiles.
It’s possible, but hard to say without testing. In this case I would think that it’s not Colibri since it was able to perform the first part of the upload correctly for all 256 studies.
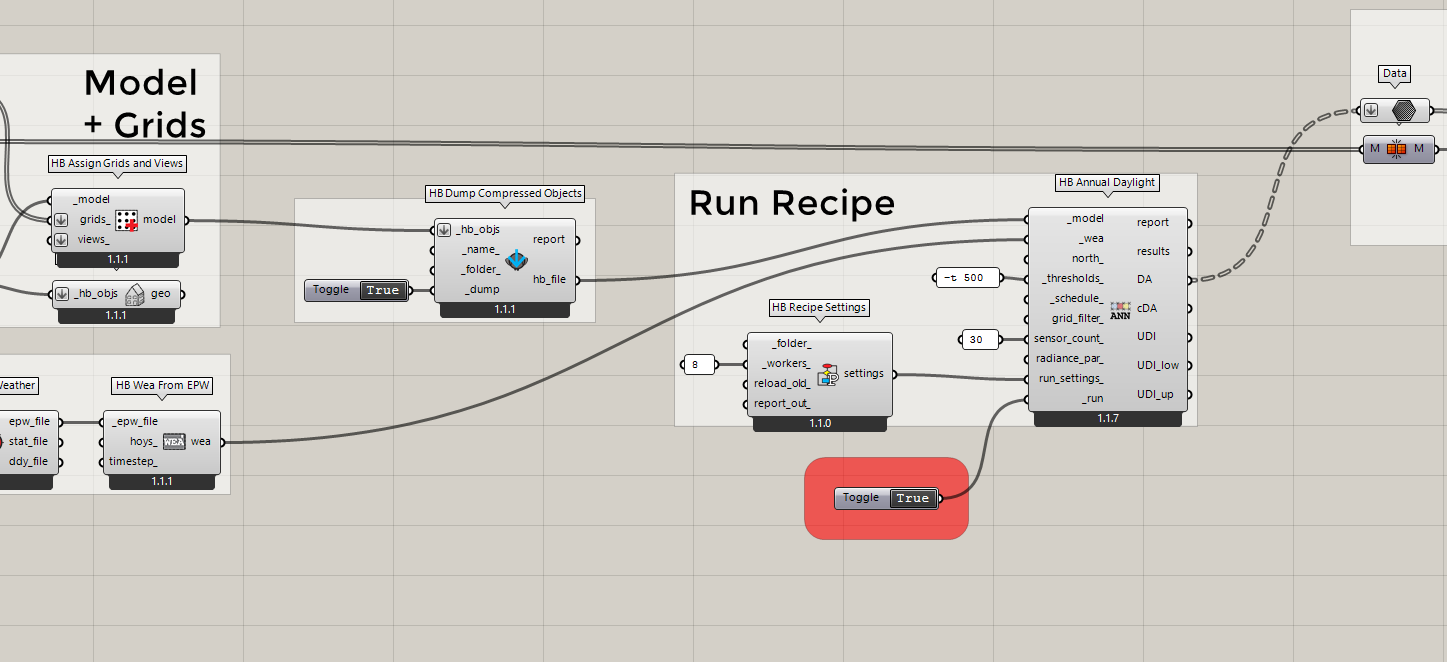
I’m sorry that I completely forgot to respond to the pickle question. If your model is huge, you can write it to a compressed file before you plug it into the Recipe component. You just plug that compressed file path into the component like so: