First of all, thank you for your help! Your interest and help in these issues gives us the confidence to complete our projects !
As you know, I purchased a professional parallel computing service for my work. In my project, I decompose a building into individual rooms for analysis (you previously suggested a more simplified approach, but I need the data for individual rooms due to the scope of my project). I understand that this approach inherently takes longer than a typical building simulation (since there are more room units), but to address this, I purchase a cloud computing service capable of running 600 parallel CPUs.
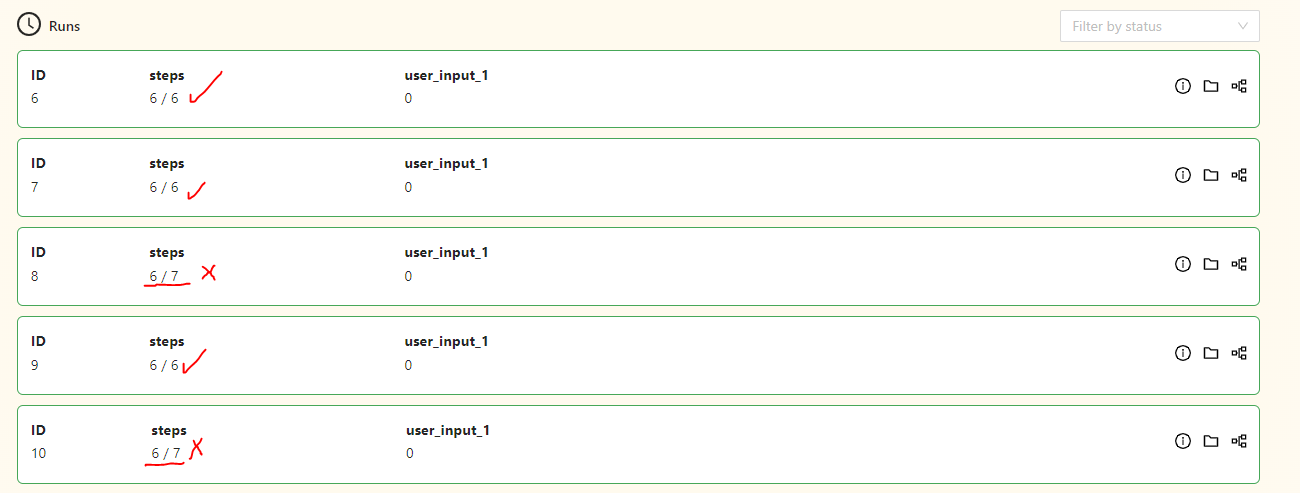
When I started the trial runs, I still felt that the analyses were progressing very slowly. I am sharing the results of the analysis for 13 two-story buildings in image 1:
In terms of time compared to the local machine, I think it is significantly faster than a normal analysis, but I think it consumes a high amount of CPU hours per unit. Additionally, it seems that the analysis could not be completed due to some errors occurring during the process.
At this point, how can I identify both the cause of these errors and whether the parallel computing system is running correctly? I need your advice about this topics also, I am working on creating a dataset for a machine learning-based study and need to perform analyses for approximately 20,000 buildings.
More CPUs don’t make a single energy simulation run faster. This is because there is no obvious way to run a single Energy simulation in parallel. You will notice the difference when running parametric studies, and you can run many studies in parallel.
There is and will be an overhead for running simulations on the cloud. At the minimum, there will be an overhead for uploading and downloading the files. But in your case, it should be much more than running them locally. See this blog post for a more in-depth explanation.
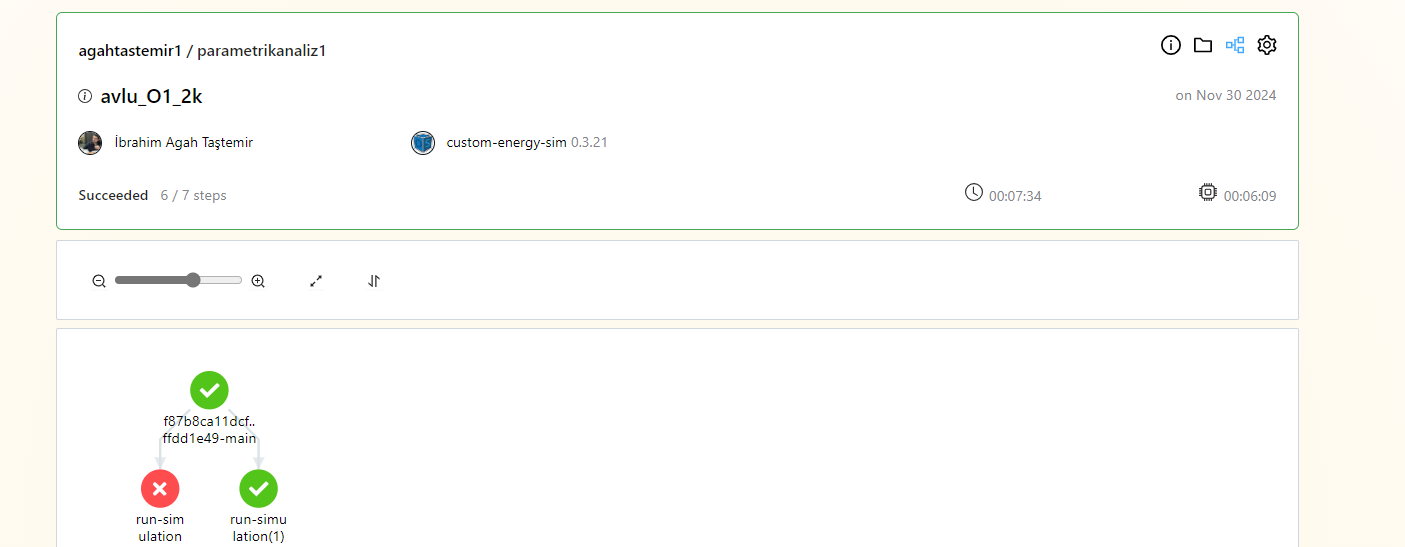
Those runs have succeeded. You can see the status on the card.
What you see there is an automated retry for a failed step. This can happen for several reasons but as long as the retry runs fine you can ignore the failed step. You can read more about why retries are needed here:
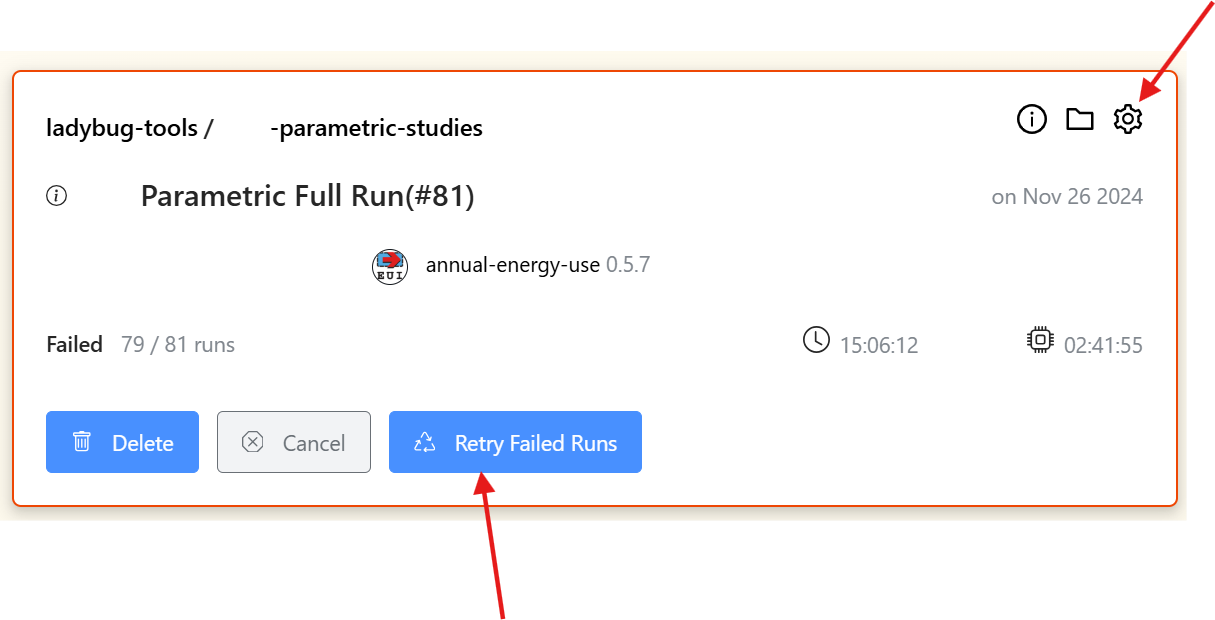
For very large studies, there will be cases that they will fail even after automated retries. You will also increase the chance of a step being killed by having single steps that take a very long time. That’s why we have a button to allow you to “Retry Failed Runs”.
As long as the retry works you can ignore the error. You should only be concerned about the final status of the run. If it succeeds, then you are good to go.
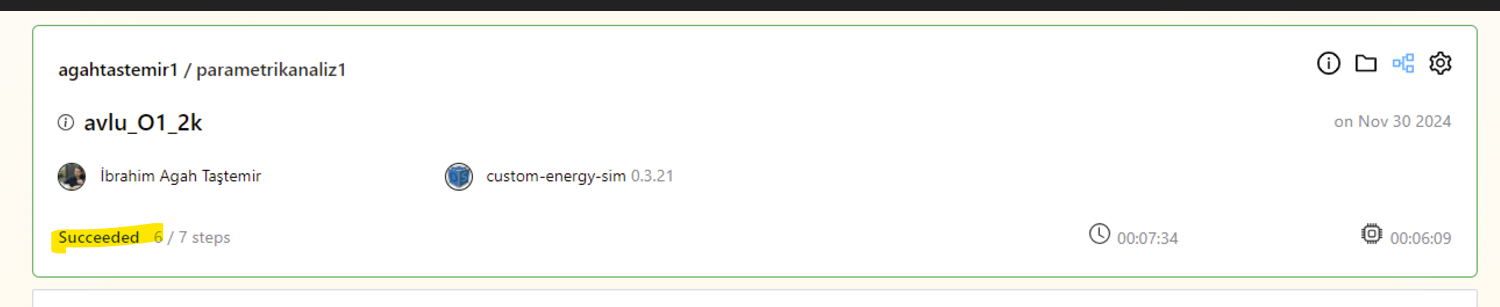
You can see the effect of parallel runs by comparing the total CPU hours and the duration. In the case of your study, the runs used 1 hour, and 49 minutes of CPU resources but it only took 10 minutes and 18 seconds to run. CPU hours/duration is the boost that you get by using parallel computing.
It’s up to you but I strongly recommend you to at least try what I suggested once and compare the results between the two. The heat transfer between the rooms in your model is going to be minimal, and you can sample the rooms, to reduce the time of the study, and still get the same results. If the results were noticeably different then it is justified to run them for all those rooms that you had in your model.
I definitely want to try the solution you suggest to improve speed, but for the data set intended for machine learning, we have designed a Colibri-based system that integrates energy analysis with the properties assigned to each cube unit. Unfortunately, if we were to switch to a simplified analysis at this point, we would increase the workload of merging data into Excel files and the probability of making mistake at this stage.
A second risk with our method is that the total CPU hours may not be sufficient for the entire project. I am really worried about this and fear that my work will remain incomplete.
At this point, is it possible to develop a recipe that is better suited to our workflow and can work faster in this context?
You know better about your project needs but if you ask me, this shouldn’t be the reason for not optimizing your models. As you scale your data you need to optimize your workflows.
You shouldn’t worry about this. We will work with you to ensure you finish your studies. We have been very forgiving when it comes to PhD and Master students.
I’m not sure if there is a need for a custom recipe. You have many more obvious steps that you can focus and improve if needed. Let’s start running your studies and see what the main pain points will be.