Hi, @max!
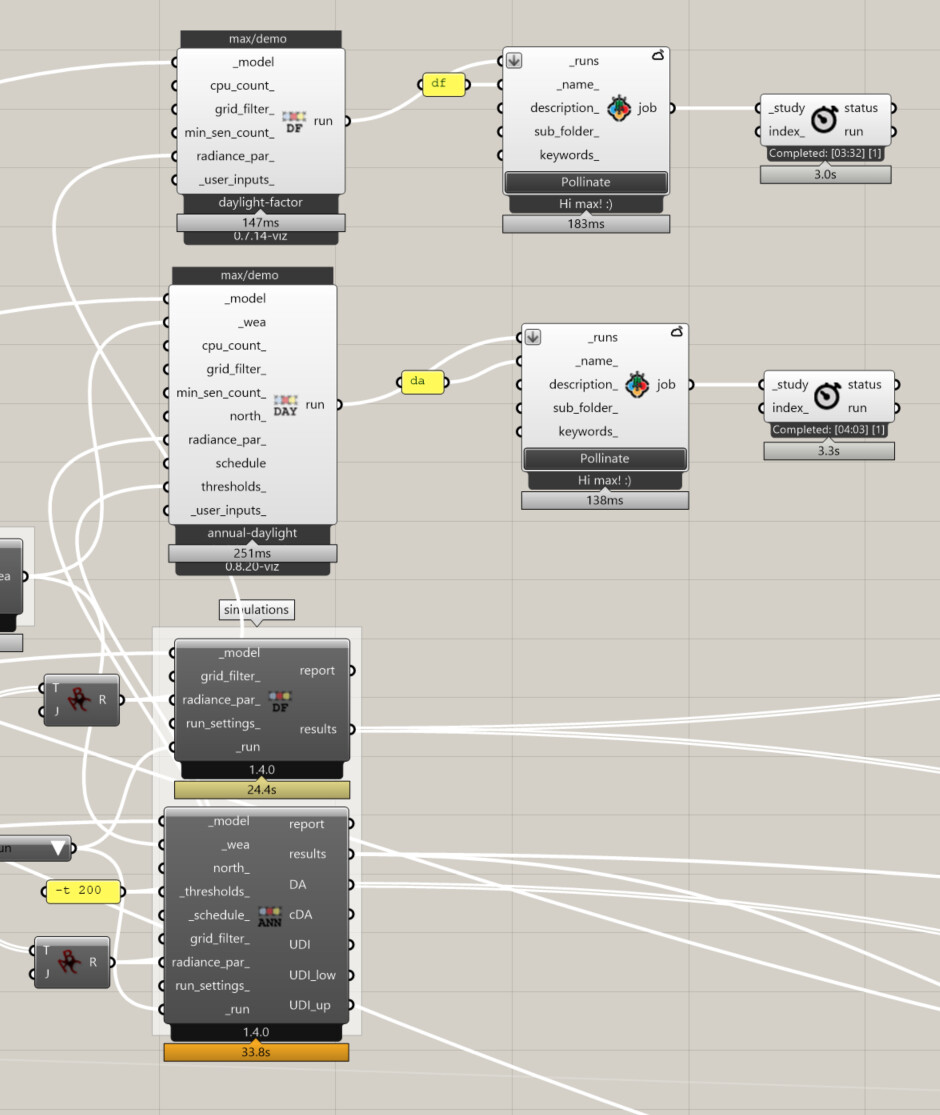
Glad to have you back.  The short answer is that most of the time that you see is the time between the steps. You get charged for the compute time and not the wait time. We are providing a better report for the correct CPU usage for each study.
The short answer is that most of the time that you see is the time between the steps. You get charged for the compute time and not the wait time. We are providing a better report for the correct CPU usage for each study.
Why is it taking much longer
Generally speaking, Pollination and other distributed computing services are not optimized for running small models. The overhead for scheduling the tasks adds up and becomes more than the benefit of distributed computing. This is documented here in a blog post:
https://www.pollination.cloud/blog/up-to-100-times-faster-with-pollination-cloud
But in Pollination in particular the difference can be really large. I ran this project to study how Pollination does with a small, a medium, and a large model:
https://app.pollination.cloud/ladybug-tools/projects/performance-benchmark
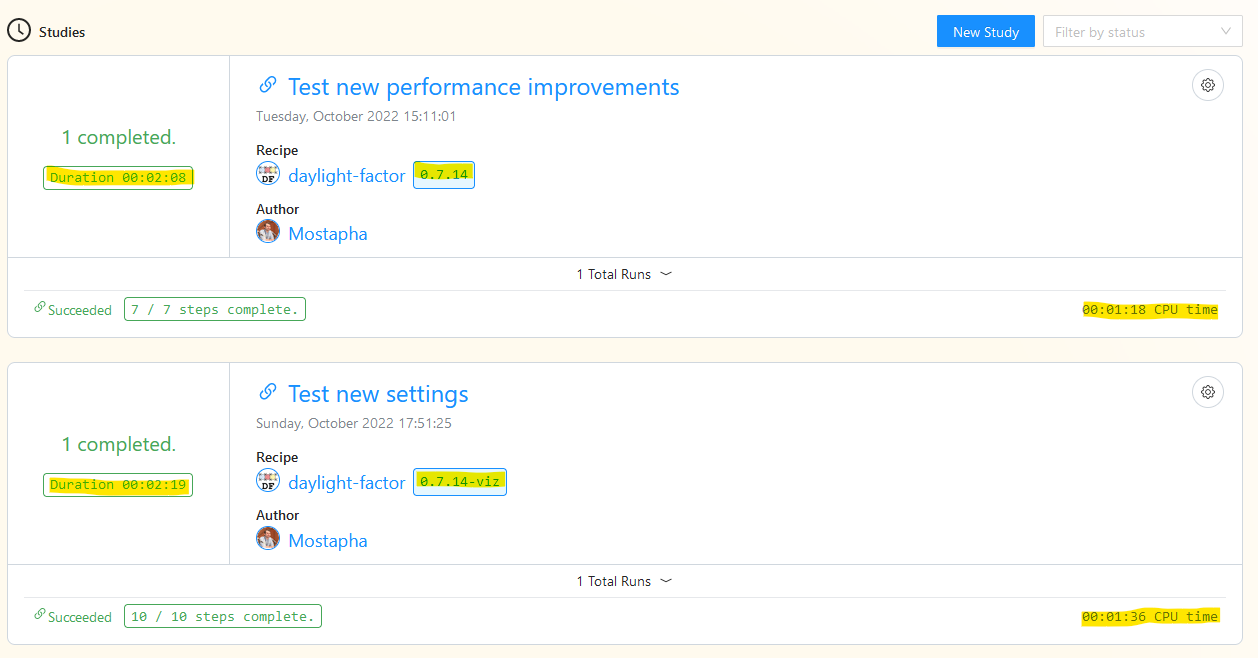
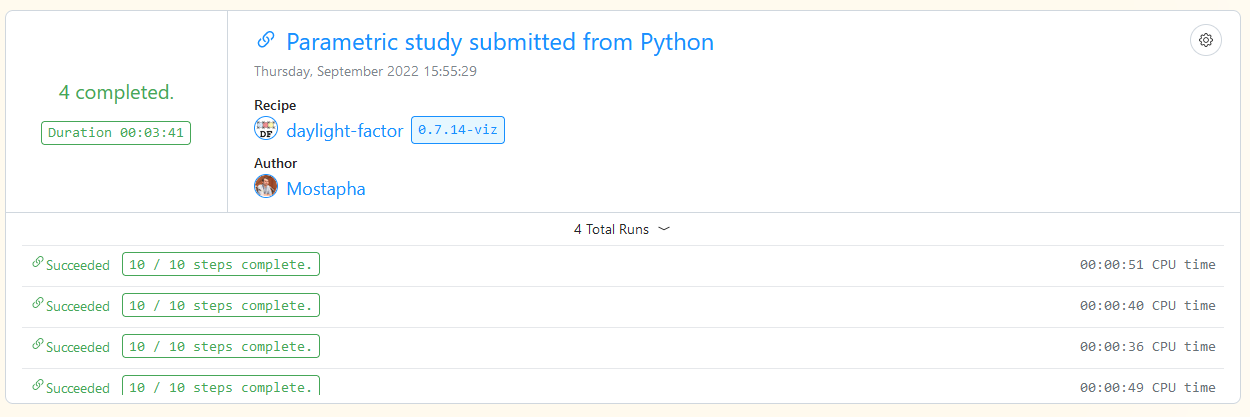
If you check the daylight-factor runs the small model, medium model and large model take 3:03, 3:01, and 4:33 to run. It does a great job for the large NREL building but the small and medium models take a long time to run. Without getting into too many details, the reason is because of scheduling the small steps and the time between the steps. Currently, Pollination checks for each step to be finished every 30 seconds. That adds up quickly if every step takes only a few seconds to run. For local runs, the check is happening every few seconds.
Is there a way to improve this
Absolutely! This is something that we have been working on improving for the last few months. We just started merging them into staging, and there will be available in production soon.
We have worked on 3 different areas:
- Simplified the progress report to minimize the number of events (already merged).
- Group the small tasks together to run on the same pod. This will minimize the overhead (ready to be merged).
- Minimize the time for checking the status of each step (ready to be merged).
There is also one other important difference that can help speed up the runs on Pollination. When the run is finished on Pollination it zips every single output of the recipe. For recipes with several outputs that can add up quickly. If you don’t need the outputs, you can remove them from the recipe.
Finally, if you have several 1000s of runs you want to include the post-processing script as part of the recipe itself so you don’t have to download every single run and post-process the results locally.
I have helped other offices to run 1000s of studies for their models by customizing the recipes for them to minimize the overhead. When is your deadline and how many models do you have? You can send me a private message to continue the conversation if you don’t want to share those details publicly.
I will keep this post open so we can post an update once all the improvements that I mentioned above are merged into production.