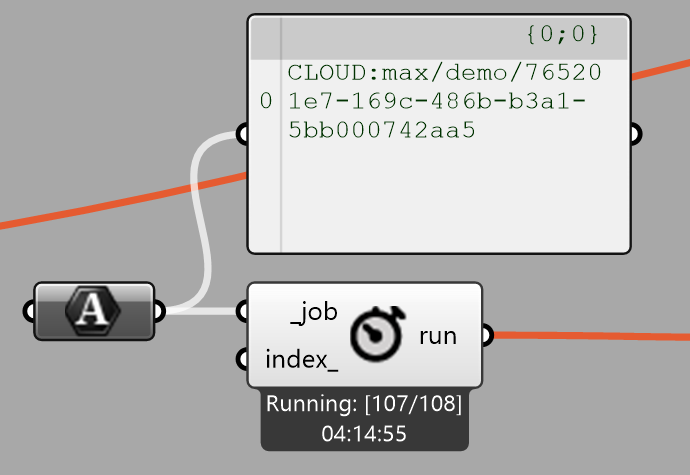
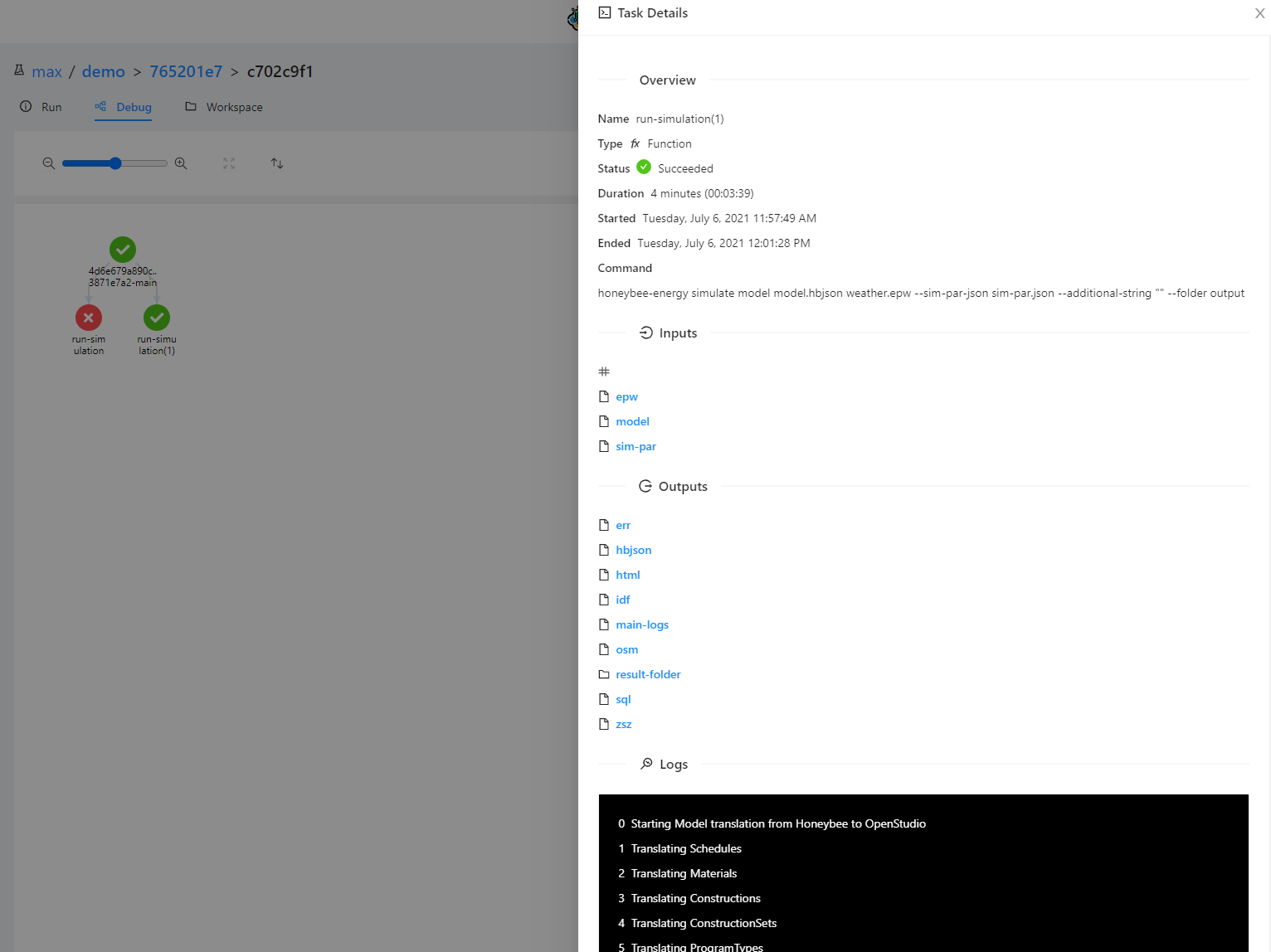
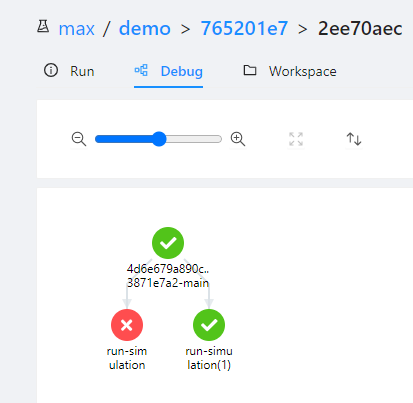
There are no error logs so I can’t figure out what went wrong. I have noticed that the two subroutines look identical (why are there two?) but that the second one completed successfully:
Thanks for bringing this to our attention, and apologies for the confusion. It looks like the run completed successfully (hence why it looks the same as the others) but our monitoring service didn’t catch that it was successful. Which is why the web application shows that it is running.
I’m going to look into this more today, but right now it looks like the service that controls the workflows was restarted while this run was in-progress which may have caused the update service to miss the change in status.
The reason that there are 2 nodes is that the workflow engine is set to re-try any failed nodes to solve errors caused by latency, e.g. trying to download a file that has not finished uploading yet.
Just to follow up on this: our run monitoring service was indeed unresponsive for several hours while this job was in-progress. We had implemented a check to prevent this from happening previously, but forgot to enable the check on our compute cluster.
I merged the necessary change earlier for testing and it will be in production soon. Apologies again for the confusion! But, thanks for using a real-world simulation, this is what we need to be able to improve the platform!